
Por: Anthony García-Marín
I. Contexto necesario
Antes de contestar esa pregunta, se deben aclarar ciertos conceptos y temas que se dan por sentado al hablar sobre esta temática. En orden de aparición en la pregunta, debemos aclarar ¿qué es una Inteligencia Artificial (IA)?
–La respuesta más sencilla es que se trata de un campo de investigación y tecnología que se ha desarrollado rápidamente en los últimos 50 años, y que ha tenido un impacto significativo en muchos aspectos de la sociedad y la economía, de la misma forma se puede plantear que es una rama de la informática que se centra en el desarrollo de algoritmos y sistemas capaces de realizar tareas que normalmente requieren inteligencia humana, como el aprendizaje, el razonamiento y la toma de decisiones.
A mediados del siglo XX, el interés por la IA comenzó a crecer, y en 1956 se llevó a cabo la primera conferencia internacional en Dartmouth College. Durante la década de 1950 y 1960, se produjo un aumento significativo en el interés y la financiación para la investigación en este campo, lo que permitió el desarrollo de nuevos algoritmos y tecnologías. En 1966, el científico de computación británico, Christopher Strachey, creó el primer programa de juegos de mesa, que podía jugar al ajedrez y al draughts. Durante los siguientes años, la investigación se centró en el desarrollo de algoritmos y sistemas basados en reglas que podrían realizar tareas específicas, como el reconocimiento de lenguaje natural y la toma de decisiones en juegos.
En los años 70 y 80, experimentó un período de expansión y popularidad, impulsado por el aumento de la capacidad de procesamiento y la disponibilidad de datos. Durante este período, la IA se aplicó a una amplia gama de problemas, incluyendo el diagnóstico médico, la planificación y la optimización, sin embargo, la IA experimentó una recesión en la financiación y el interés, conocida como la «primera era oscura» de la IA, cuando se dieron cuenta de que algunos de los avances anteriores eran más limitados de lo que se pensaba inicialmente. Sin embargo, en 1981, el científico de la computación canadiense, Geoffrey Hinton, desarrolló el algoritmo de retropropagación, que ha sido fundamental para el desarrollo de la red neuronal profunda y la IA de aprendizaje profundo -lo cual desarrollaremos más adelante. la IA.
En 1997, el programa de ajedrez de IBM, Deep Blue, se convirtió en el primer programa de computadora en derrotar a un campeón mundial de ajedrez, Garry Kasparov. Este logro fue un hito importante en la historia de la IA, y demostró la capacidad de la IA para realizar tareas que antes se consideraban exclusivas de los humanos.
En la década de 1990 y 2000, la IA experimentó un renacimiento con el surgimiento de nuevos enfoques y tecnologías, como el aprendizaje profundo y el aprendizaje automático. Estos nuevos enfoques permitieron a los sistemas de IA aprender y mejorar de manera autónoma a partir de grandes cantidades de datos, lo que permitió una mayor eficacia y escalabilidad en la solución de problemas complejos. Aparejado de un aumento significativo en la financiación y el interés en el campo. Para el año 2012, el algoritmo de aprendizaje profundo de Hinton, AlexNet, ganó el concurso de visión por computadora ImageNet, superando a los humanos en la identificación de imágenes. Este logro fue un punto de inflexión en el desarrollo de la IA, y sentó las bases para la popularidad y el uso actual de la IA en una amplia variedad de aplicaciones.
En los últimos años, el desarrollo y la aplicación de la IA se ha acelerado a un ritmo sin precedentes, se ha utilizado en una amplia variedad de industrias y aplicaciones, incluyendo la banca, la salud, la agricultura, la robótica, la automoción y la logística. Hasta la actualidad podemos agrupar según el tipo:
- IA débil o limitada: también conocida como IA de tarea única, esta forma de IA se enfoca en resolver una tarea específica de manera efectiva, pero no tiene la capacidad de transferir su conocimiento a otras tareas.
- IA fuerte o general: también conocida como IA de conciencia, esta forma de IA busca simular la inteligencia humana en una variedad de tareas y capacidades, incluyendo la conciencia, la resolución de problemas y la comprensión de lenguaje natural.
- IA supervisada: este tipo de IA se entrena en un conjunto de datos etiquetados, donde se le proporcionan las entradas y las salidas esperadas, y luego se le permite hacer predicciones precisas en datos nuevos y desconocidos.
- Google Photos (Android, iOS) – para clasificar imágenes y ofrecer funciones como la búsqueda de imágenes y la creación de álbumes automáticos.
- Shazam (Android, iOS) – para reconocer canciones y ofrecer información sobre ellas.
- IA no supervisada: este tipo de IA se entrena en un conjunto de datos sin etiquetas, y se enfoca en encontrar patrones y estructuras ocultas en los datos.
- Spotify (Android, iOS) – para recomendar música y listas de reproducción basadas en el historial de escucha y preferencias del usuario.
- Netflix (Android, iOS) – para recomendar programas y películas basadas en el historial de visualización y preferencias del usuario.
- IA por refuerzo: en este tipo de IA, el modelo aprende a través de la interacción con su entorno y recibiendo retroalimentación en forma de recompensas y castigos.
- Pokémon Go (Android, iOS) – para controlar el comportamiento de los Pokémon en el juego y para ofrecer recompensas y desafíos al jugador.
- Siri (iOS) – para mejorar las respuestas a las preguntas y las acciones del usuario a lo largo del tiempo.
- IA distribuida: en este tipo de IA, múltiples sistemas trabajan juntos para resolver un problema complejo, compartiendo datos y colaborando en tiempo real.
- Google Assistant (Android, iOS) – para integrar diferentes servicios de Google y proporcionar una experiencia de asistente personalizada.
- Amazon Alexa (Android, iOS) para integrar diferentes servicios de Amazon y proporcionar una experiencia de asistente personalizada.
Pese a esta larga historia en el desarrollo, aplicación y uso cotidiano de diversas AI, tanto en la industria como en la vida diaria, la pregunta que surge es: ¿a qué se debe el aumento del interés en los últimos meses sobre esta tecnología?
La respuesta se llama ChatGP, el cual es un modelo de lenguaje de gran escala desarrollado por OpenAI. Se entrenó utilizando una gran cantidad de texto en Internet[1], lo que le permite responder a una amplia gama de preguntas y realizar tareas como la generación de texto, la traducción y la respuesta a preguntas de diversa índole, incluso la generación de ensayos académicos en formato APA 7ma edición, con sus respectivas citas y referencias bibliográficas -lo que encendió las alarmas de docentes a nivel de educación secundaria y universitaria.
El modelo utiliza una arquitectura de Transformer, que es un tipo de red neuronal diseñada específicamente para procesar secuencias de datos, como texto. La red neuronal se entrena utilizando un proceso llamado aprendizaje profundo supervisado[2], donde se le proporciona una gran cantidad de ejemplos de texto con las respuestas correctas y se le permite aprender a través de la comparación de sus propias respuestas con las respuestas correctas.
Como indicamos, pese a un largo desarrollo, el concepto de IA se remonta a la década de 1950, cuando se formuló por primera vez por el matemático y lógico británico Alan Turing. Sin embargo, uno de los primeros sistemas de IA que se desarrollaron fue el programa Eliza, desarrollado por el psicólogo Joseph Weizenbaum en 1966. Eliza era un programa de chat simple que utilizaba patrones simples de respuesta y una estrategia de «reflejo de Rogerian» para simular una conversación con un terapeuta. Aunque no era realmente inteligente, Eliza demostró la capacidad de los ordenadores para simular conversaciones humanas y fue un hito en el desarrollo de la IA.
El segundo concepto por aclarar en la pregunta, que inspira la publicación de este post, es que no se trata de un examen de admisión, sino de una Prueba de Aptitud Académica lo que se aplica año a año durante el proceso de admisión a las universidades públicas del país, así como en otros países, desde mediados de los años sesenta del siglo pasado.
En el caso de nuestro país, el Instituto de Investigaciones Psicológicas de la Universidad de Costa Rica (IIP-UCR) ha estado al frente de la realización, ejecución y evaluación de la prueba, en la cual indican que dicha prueba “mide el razonamiento en contextos verbales y matemáticos. Los ítems miden el nivel de razonamiento del (de la) aspirante, evaluando su capacidad para utilizar material verbal mediante el uso de las estrategias requeridas para resolver los ítems de la Prueba: suponer, presuponer, parafrasear, oponer, deducir y reducir. También, la PAA tiene ítems de razonamiento en contexto matemático, los cuales miden la habilidad de los (las) aspirantes para manejar y aplicar las estrategias de generalizar, verificar, indagar y representar, en conjunto con las nociones de conceptos básicos matemáticos para la solución de situaciones.”
II. Sobre la PAA
Para contestar a la pregunta inicial, nos dispusimos a realizar la PAA con la ayuda de ChatGPT. Realizamos la prueba que ofrece el IIP-UCR en su página web: Práctica en línea | Prueba de Aptitud Académica (ucr.ac.cr) dispuesto para las personas aspirantes que deseen realizar a modo de práctica y prepararse para el proceso de admisión a la UCR. Dicha práctica consta de 75 preguntas, las cuales se realizan mediante un cuestionario en línea de Google Forms. Este formato posee la ventaja que al finalizar se puede obtener el puntaje de preguntas acertadas de forma correcta. Esto nos permitió determinar si la AI era capaz de obtener la cantidad de puntos necesarios para ingresar a la UCR, además conocer las áreas de mayor o menor fortaleza.
El tiemplo empleado en ejecutar la prueba fue de 58 minutos, para contestar a las 75 preguntas del cuestionario, es decir, copiar y pegar la pregunta en el ChatBoot de ChatGPT, obtener la respuesta y colocar la respuesta que se obtuvo en el cuestionario. Para este ejercicio, no se detuvo a revisar las preguntas de la PAA o las respuestas del ChatGPT, solo se hizo el proceso para saber la capacidad de la AI.
Al haber contestado las preguntas, obtuvimos que ChatGPT fue capaz de proporcionar 51 respuestas -68%- de forma correcta. Por otro lado, solo en una ocasión nos ofreció dos posibles respuestas, de las cuatro opciones disponibles, es decir, no contestó de forma correcta. Así mismo, en las preguntas en las que más “falló”, fue en aquellas en las que se solicitaba inferir de un párrafo una certeza o las de pensamiento deductivo-matemático.
A continuación, se muestra unas capturas de pantallas de las preguntas y respuestas:
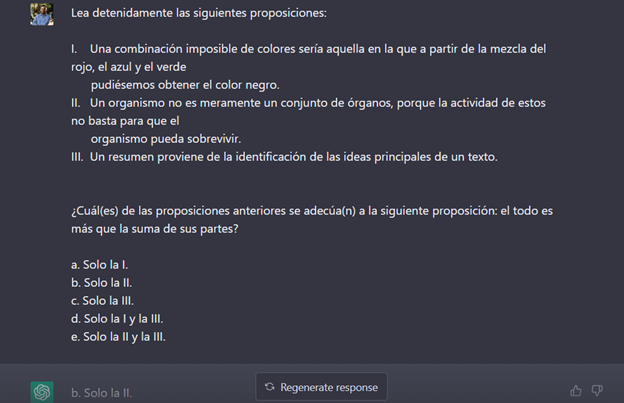


Como se observa en la segunda imagen, a parte de la respuesta solicitada, ChatGPT nos ofrece una explicación del procedimiento llevado acabo para obtener la respuesta. En el caso de la tercera imagen, a partir de la información proporcionada no le fue posible obtener una respuesta.
III. A modo de cierre
El ejercicio anterior tenía varios propósitos. El primero de ellos es presentar y discutir sobre la historia de la inteligencia artificial y en particular sobre ChatGPT, ya que como se mencionó, esta es la AI más potente de acceso libre hasta el momento. Las técnicas de aprendizaje supervisado profundo mediante redes neuronales han demostrado una gran capacidad para predecir con gran exactitud, las predicciones solicitadas mediante su entrenamiento con un gran volumen de datos, es por ello por lo que tenemos acá la intersección de modelos matemáticos, informática, ciencia de datos, estadística y big data.
Por otro lado, proponer, a modo de sugerencia, la vital importancia que recobra una pedagogía basada en la pregunta. La AI no tiene preguntas, tiene respuestas programadas que las realiza con millones de procesos en fracciones de segundo, pero por más que se programe para tener cualidades humanas, no posee hasta el momento la capacidad para imaginar.
La incorporación de las herramientas tecnológicas en el aula pasa por una mediación pedagógica, basada en una relación horizontal. Donde la pedagogía de la pregunta, que planteaba P. Freire, ante la cultura del silencio y teoría antidialógica de la educación tradicional, que se resiste al cambio, es más que necesaria, es dentro del aula donde no podemos prescindir de la imaginación y la creatividad para defender una educación liberadora. No se trata de volver a los exámenes rígidos y presenciales, se trata de cuestionarnos sobre la mediación que realizamos con las y los estudiantes.
Para finalizar, podemos concluir que la AI pudo aprobar la PAA para ingresar a la UCR, lo cual no implica que tenga o posea aptitudes académicas para la educación superior, de la misma forma tuvo la capacidad para redactar gran parte del texto utilizado en este post, lo que la AI no pudo hacer, fue imaginar esta entrada para el blog del Centro Agenda Joven, sus apartados y la excusa del examen de admisión. También tuvo la capacidad de crear la imagen del principio que ilustra este texto, lo que no hizo fue imaginar a un estudiante universitario que estuviese realizando un examen al estilo de “Una noche estrellada” de V. Van Gogh.
[1] Utilizando la tecnología PT-3 (Generative Pretrained Transformer 3) el cual fue entrenado con una cantidad masiva de datos de texto en Internet, aproximadamente 45 terabytes de información. Este enorme corpus de datos incluye noticias, artículos, blogs, foros, libros, páginas web, y mucho más, lo que le permite a GPT-3 tener un conocimiento amplio y variado sobre una gran cantidad de temas. El entrenamiento de GPT-3 requiere una gran cantidad de recursos computacionales, incluyendo un cluster de GPUs de alta potencia. GPT-3 es actualmente uno de los modelos de lenguaje más grandes y avanzados que se han desarrollado hasta el momento y su capacidad para generar texto coherente y convincente ha sido un hito en el desarrollo de la IA.
[2] El aprendizaje profundo supervisado es una técnica de aprendizaje automático que se utiliza para entrenar modelos de inteligencia artificial en tareas predictivas. En este tipo de aprendizaje, se proporciona al modelo un conjunto de datos de entrenamiento que incluye tanto las entradas como las etiquetas correctas (o salidas esperadas). El modelo entonces aprende a generalizar de estos datos para hacer predicciones precisas en datos desconocidos.
El aprendizaje profundo supervisado es una técnica de aprendizaje automático que se aplica a redes neuronales profundas, también conocidas como redes de aprendizaje profundo. Una red neuronal profunda es una red compuesta por muchas capas ocultas, cada una de las cuales aprende una representación más abstracta y característica de los datos a medida que se procesan a través de ellas.
El proceso de entrenamiento consiste en ajustar los pesos de las conexiones entre las neuronas de la red de manera que minimicen la diferencia entre las salidas previstas y las etiquetas correctas. Esto se logra utilizando un algoritmo de optimización, como el gradiente descendente, que actualiza los pesos en la dirección opuesta a la gradiente de una función de pérdida que mide la precisión de las predicciones.


